JVM第三篇,类加载。
1. 类文件结构 这一节真的很硬核,很枯燥,( ఠൠఠ )ノ。
以简单的HelloWorld.java为例
1 2 3 4 5 public class HelloWorld { public static void main (String[] args) { System.out.println("hello world" ); } }
1 javac -parameters -d . HelloWorld.java # 编译为字节码文件
编译字节码文件
根据JVM规范,类文件结构如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ClassFile{ u4 magic; u2 minor_version; u2 major_version; u2 constant_pool_count; cp_info constant_pool[constant_pool_count-1 ]; u2 access_flags; u2 this_class; u2 super_class; u2 interfaces_count; u2 interfaces[interfaces_count]; u2 fields_count; field_info fields[fields_count]; u2 methods_count; method_info methods[methods_count]; u2 attributes_count; attribute_info attributes[attributes_count]; }
1.1 魔数 0-3字节,表示它是否是class类型的文件。
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
1.2 版本 4-7字节,表示类的版本,00 34(十六进制,转换十进制为52)表示是Java 8。
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
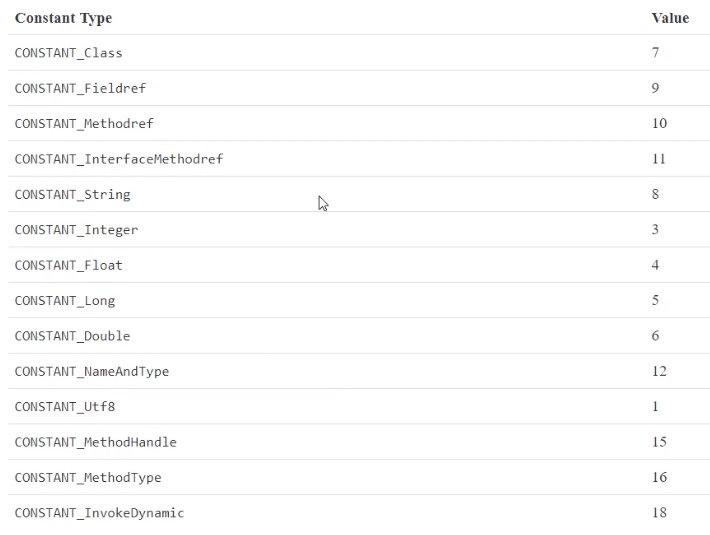
1.3 常量池
8-9字节,表示常量池长度,00 23(35)表示常量池中有#1-#34项,#0不计入也没有值。
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
第#1项0a表示一个Method信息(由上表查询可知Methoddef),00 06和00 15(21)表示它引用了常量池中#6和#21项来获取这个方法的所属类和方法名。
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09
第#2项 09 表示一个 Field 信息,00 16(22)和 00 17(23)表示它引用了常量池中 #22 和 # 23 项
0000000 ca fe ba be 00 00 00 34 00 23 0a 00 06 00 15 09 00 16 00 17 08 00 18 0a 00 19 00 1a 07 00 1b 07
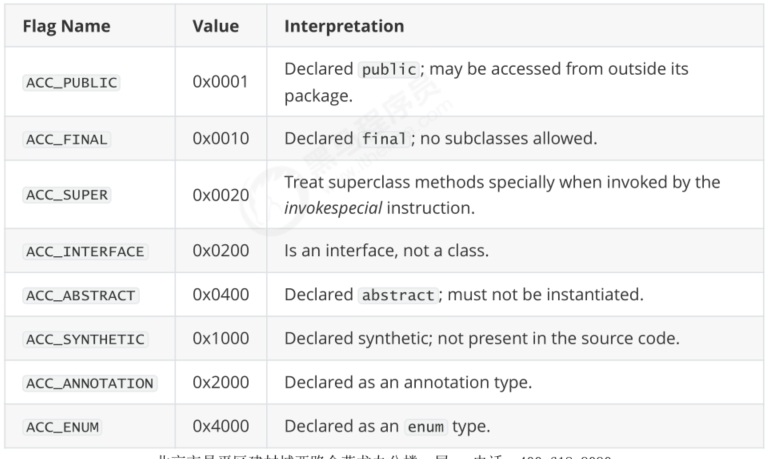
1.4 访问标识与继承信息 21 表示该 class 是一个类,公共的
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
05 表示根据常量池中 #5 找到本类全限定名
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
06 表示根据常量池中 #6 找到父类全限定名
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
0 表示接口的数量,本类为 0
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
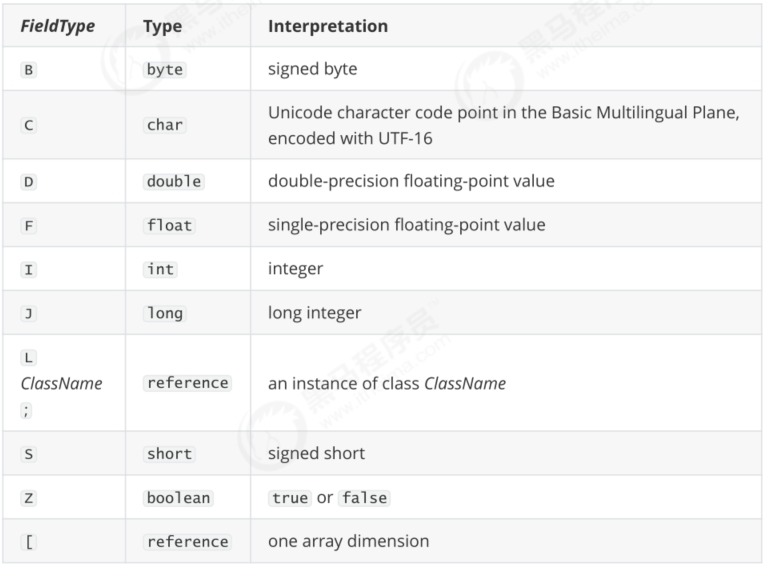
1.5 Field信息 0 表示成员变量数量,本类为0
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
1.6 Method信息 0002表示方法数量,本类为2
0000660 29 56 00 21 00 05 00 06 00 00 00 00 00 02 00 01
一个方法由 访问修饰符,名称,参数描述,方法属性数量,方法属性组成。
1.7 附加属性
00 01 表示附加属性数量
00 13 表示引用了常量池 #19 项,即【SourceFile】
00 00 00 02 表示此属性的长度
00 14 表示引用了常量池 #20 项,即【HelloWorld.java】
0001100 00 12 00 00 00 05 01 00 10 00 00 00 01 00 13 00
参考文献
2. 字节码指令 2.1 入门 上一节中构造方法的字节码指令
2a b7 00 01 b1
通过查询上方参考文献,知:
2a => aload_0 加载 slot 0 的局部变量,即 this,做为下面的 invokespecial 构造方法调用的参数
b7 => invokespecial 预备调用构造方法,哪个方法呢?
00 01 引用常量池中 #1 项,即【 Method java/lang/Object.“”:()V 】
b1 表示返回
主方法的字节码指令
b2 00 02 12 03 b6 00 04 b1
b2 => getstatic 用来加载静态变量,哪个静态变量呢?
00 02 引用常量池中 #2 项,即【Field java/lang/System.out:Ljava/io/PrintStream;】
12 => ldc 加载参数,哪个参数呢?
03 引用常量池中 #3 项,即 【String hello world】
b6 => invokevirtual 预备调用成员方法,哪个方法呢?
00 04 引用常量池中 #4 项,即【Method java/io/PrintStream.println:(Ljava/lang/String;)V】
b1 表示返回
2.2 javap工具 1 javap -v HelloWorld.class
2.3 图解过程 琐碎,P108-128。
3. 编译期处理 语法糖,就是java编译器把java文件编译为class字节码的过程中,自动生成和转换的一些代码,主要是为了减轻程序员的负担。
参见请给我一颗语法糖
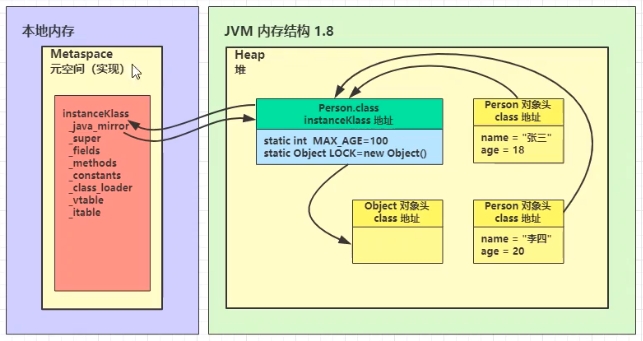
4. 类加载阶段 4.1 加载 将类的字节码加载到方法区中。内部采用C++的instanceKLass描述Java类,他重要的field有:
_java_mirror即java的类镜像,例如对String来说,就是String.class,作用是把kclass暴露给java使用。
_super即父类
_fields即成员变量
_methods即方法
_constants即常量池
_class_loader即类加载器
_vtable虚方法表
_itable接口方法表
如果这个类还有父类没有加载,先加载父类。
加载和链接可能是交替运行的。
instanceKlass这样的元数据是存储在方法区(1.8后的元空间内),但_java_mirror是存储在堆内的。
4.2 链接 验证 验证类是否符合JVM规范,安全性检查。
用UE等支持二进制的编辑器修改HelloWord.class的魔数,控制台报错ClassFormatError。
准备 为jstatic变量分配空间,设置默认值。
static变量在JDK7之前存储于instanceKlass末尾,从JDK7开始,存储于_java_mirror末尾。
static变量分配空间和赋值是两个步骤,分配空间在准备阶段完成,赋值在初始化阶段(构造方法)完成。
如果static变量是final的基本类型,那么编译阶段值就确定了,赋值在准备阶段完成。
如果static变量是final的,但属于引用类型,那么赋值也会在初始化阶段完成。
解析 将常量池中的符号引用解析为直接引用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Load { public static void main (String[] args) throws ClassNotFoundException, IOException{ ClassLoader classloader = Load2.class.getClassLoader(); Class<?> c = classloader.loadClass("类全限定类名.C" ); new C (); System.in.read(); } } class C { D d = new D (); } class D {}
4.3 初始化 <cinit>()V方法 初始化即调用<cinit>()V,虚拟机会保证这个类的构造方法的线程安全。
发生的时机 概括的说,类的初始化是懒惰的。
main方法所在的类,总会被首先初始化。
首次访问这个类的静态变量或静态方法时
子类初始化,如果父类还没初始化,会引发
子类访问父类的静态变量,只会触发父类的初始化
Class.forName
new会导致初始化
不会导致类初始化的情况
访问类的static final的静态常量(基本类型和字符串)不会触发初始化,在链接时候就完成了
访问类对象.class不会触发初始化
创建该类的数组不会触发初始化
类加载器的loadClass方法
Class.forName的参数2为false时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class Load { static { System.out.println("main init" ); } public static void main (String[] args) throws ClassNotFoundException { System.out.println(); System.out.println(B.class); System.out.println(new B [0 ]); ClassLoader c1 = Thread.currentThread().getContextClassLoader(); c1.loadClass("java.Load.B" ); ClassLoader c2 = Thread.currentThread().getContextClassLoader(); Class.forName("java.Load.B" , false , c2); System.out.println(A.a); System.out.println(B.c); System.out.println(B.a); Class.forName("java.Load.B" ); } class A { static int a = 0 ; static { System.out.println("a init" ); } } class B extends A { static final double b = 5.0 ; static boolean c = false ; static { System.out.println("b init" ); } }
4.4 练习 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Load { public static void main (String[] args) { System.out.println(E.a); System.out.println(E.b); System.out.println(E.c); } } class E { public static final int a = 10 ; public static final String b = "hello" ; public static final Integer c = 20 ; static { System.out.println("init E" ); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Load { public static void main (String[] args) { Singleton.test(); Singleton.getInstance(); } } class Singleton { private Singleton () {} public static void test () { System.out.println("test" ); } private static class LazyHolder { private static final Singleton INSTANCE = new Singleton (); static { System.out.println("lazy hoder init" ); } } public static Singleton getInstance () { return LazyHolder.INSTANCE; } }
5. 类加载器 以JDK8为例
名称
加载哪的类
说明
Bootstrap ClassLoader 启动类加载器
JAVA_HOME/jre/lib
无法直接访问
Extension ClassLoader 扩展类加载器
JAVA_HOME/jre/lib/ext
上级为 Bootstrap,显示为 null
Application ClassLoader 应用程序类加载器
classpath
上级为 Extension
自定义类加载器
自定义
上级为 Application
先层级问上级是否加载过,都没有加载过才轮到自己加载。
5.1 启动类加载器 用Bootstrap类加载器加载类:
1 2 3 4 5 public class F { static { System.out.println("bootstrap F init" ); } }
1 2 3 4 5 6 public class Load { public static void main (String[] args) throws ClassNotFoundException { Class<?> aClass = Class.forName("cn.itcast.jvm.t3.load.F" ); System.out.println(aClass.getClassLoader()); } }
控制台编译
1 2 3 4 5 java -Xbootclasspath/a:. top.tyzhang.Load # /a:.表示将当前目录追加到bootclasspath后 # 使用该方法替代核心类 # java -Xbootclasspath:<new bootclasspath> # java -Xbootclasspath/a:<追加路径> 后追加 # java -Xbootclasspath/p:<追加路径> 前追加
输出
5.2 扩展类加载器 类加载规则验证
1 2 3 4 5 public class G { static { System.out.println("classpath G init" ); } }
1 2 3 4 5 6 7 8 9 public class Load { public static void main (String[] args) throws ClassNotFoundException { Class<?> aClass = Class.forName("cn.itcast.jvm.t3.load.G" ); System.out.println(aClass.getClassLoader()); } }
写一个同名类
1 2 3 4 5 public class G { static { System.out.println("ext G init" ); } }
打个jar包
1 jar -cvf my.jar top/tyzhang/G.class
拷贝到JAVA_HOME/jre/lib/ext,重新执行 Load5_2
重新执行Load
输出
1 2 ext G init sun.misc.Launcher$ExtClassLoader@29453f44
5.3 双亲委派模式 所谓的双亲委派,就是指调用类加载器的loadClass方法时,查找类的规则。这里的双亲翻译为上级更合适,因为他们没有继承关系。
源代码。
5.4 线程上下文类加载器 打破双亲委派机制,实现逆向调用类加载器来加载当前线程中类加载器加载不到的类。
1 2 3 Class.forName("com.mysql.jdbc.Driver" ); con=DriverManager.getConnection("jdbc:mysql://localhost:3306/tsetjdbc" , "root" , "123456" );
其实没有第一句,也能正常运行,就是因为线程上下文类加载器。在DriverManager.getConnection()中,调用类的静态方法会初始化该类,进而执行该类的静态代码块,DriverManager的静态代码块:
1 2 3 4 5 6 7 8 public class DriverManager { private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList <>(); static { loadInitialDrivers(); println("JDBC DriverManager initialized" ); }
打印DriverManager的类加载器:
1 System.out.println(DriverManager.class.getClassLoader());
表示它的类加载器是Bootstrap ClassLoader,回到JAVA_HOME/jre/lib下搜索类,但是该目录下显然并没有mysql的jar包,继续查看loadInitialDriver()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 private static void loadInitialDrivers () { String drivers; try { drivers = AccessController.doPrivileged(new PrivilegedAction <String>() { public String run () { return System.getProperty("jdbc.drivers" ); } }); } catch (Exception ex) { drivers = null ; } AccessController.doPrivileged(new PrivilegedAction <Void>() { public Void run () { ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class); Iterator<Driver> driversIterator = loadedDrivers.iterator(); try { while (driversIterator.hasNext()) { driversIterator.next(); } } catch (Throwable t) { } return null ; } }); if (drivers == null || drivers.equals("" )) { return ; } String[] driversList = drivers.split(":" ); println("number of Drivers:" + driversList.length); for (String aDriver : driversList) { try { println("DriverManager.Initialize: loading " + aDriver); Class.forName(aDriver, true , ClassLoader.getSystemClassLoader()); } catch (Exception ex) { println("DriverManager.Initialize: load failed: " + ex); } } }
先看3说明最后使用的是Class.forName完成类的加载和初始化,关联的是应用程序类加载器,因此可以顺利完成类加载。
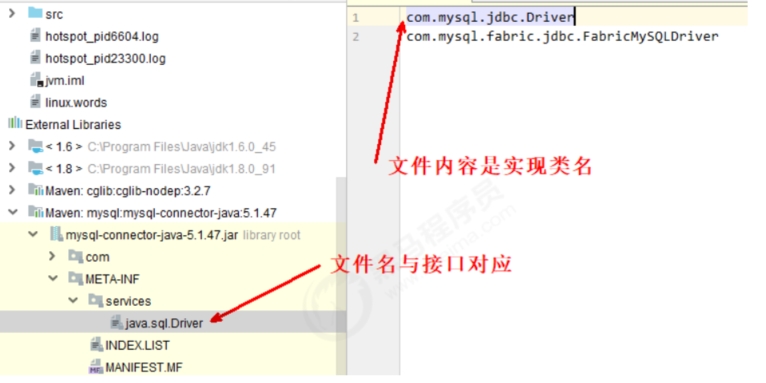
1就是Service Provider Interface(SPI),约定如下,在jar包中的META-INF/services包下,以接口全限定名为文件,文件内容是实现类名称。
这样就可以使用:
1 2 3 4 5 ServiceLoader<接口类型> allImpls = ServiceLoader.load(接口类型.class); Iterator<接口类型> iter = a;;Impls.iterator(); while (iter.hasNext()){ iter.next(); }
来得到实现类,体现的是面向接口编程+解耦的思想,在以下框架中都运用了此思想:
JDBC
Servlet初始化器
Spring容器
Dubbo(对SPI进行了扩展)
继续看上述代码中的ServiceLoad.load方法:
1 2 3 4 5 public static <S> ServiceLoader<S> load (Class<S> service) { ClassLoader cl = Thread.currentThread().getContextClassLoader(); return ServiceLoader.load(service, cl); }
线程上下文类加载器是当前线程使用的类加载器,默认是应用程序类加载器,它的内部又是由CLass.forName调用了线程上下文类加载器完成类加载。具体代码在ServiceLoader的内部类LazyIterator中。
适用场景:
当高层提供了统一接口让低层去实现,同时又要是在高层加载(或实例化)低层的类时,必须通过线程上下文类加载器来帮助高层的ClassLoader找到并加载该类。
当使用本类托管类加载,然而加载本类的ClassLoader未知时,为了隔离不同的调用者,可以取调用者各自的线程上下文类加载器代为托管。
5.5 自定义类加载器 应用场景
想加载非classpath随意路径中的类文件
都是通过接口来实现,希望解耦时,常用在框架设计
这些类希望予以隔离,不同应用的同名类都可以加载,不冲突,常见于tomcat容器
步骤
继承ClassLoader父类
要遵从双亲委派机制,重写findClass方法
不是重写loadClass方法,否则不会走双亲委派机制
读取类文件的字节码
调用父类的defineClass方法来加载类
使用者调用该类加载器的loadClass方法
例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class MyClassLoader extends ClassLoader { @Override protected Class<?> findClass(String name) throws ClassNotFoundException{ String path = "e:\\myclasspath\\" + name + ".class" ; try { ByteArrayOutputStream os = new ByteArrayOutputStream (); Files.copy(Paths.get(path), os); byte [] bytes = os.tobyteArray(); return defineClass(name, bytes, 0 , bytes.length); } catch (IOException e){ e.printStackTrace(); throw new ClassNotFoundException ("类文件未找到" , e); } } }
1 2 3 4 5 6 7 8 9 MyClassLoader classLoader = new MyClassLoader ();Class<?> c1 = classLoader.loadClass("name1" ); Class<?> c2 = classLoader.loadClass("name1" ); System.out.println(c1 == c2); MyClassLoader classLoader2 = new MyClassLoader ();Class<?> c3 = classLoader.loadClass("name1" ); System.out.println(c1 == c3); c1.newInstance();
6. 运行期优化 6.1 即时编译 分层编译 1 2 3 4 5 6 7 8 9 10 11 12 public class JIT1 { public static void main (String[] args) { for (int i = 0 ; i < 200 ; i++) { long start = System.nanoTime(); for (int j = 0 ; j < 1000 ; j++) { new Object (); } long end = System.nanoTime(); System.out.printf("%d\t%d\n" ,i,(end - start)); } } }
JVM 将执行状态分成了 5 个层次:-
0 层,解释执行(Interpreter)
1 层,使用 C1 即时编译器编译执行(不带 profiling)
2 层,使用 C1 即时编译器编译执行(带基本的 profiling)
3 层,使用 C1 即时编译器编译执行(带完全的 profiling)
4 层,使用 C2 即时编译器编译执行
即时编译器(JIT)与解释器的区别
解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释。JIT 是将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译。解释器是将字节码解释为针对所有平台都通用的机器码。JIT 会根据平台类型,生成平台特定的机器码。对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1(提升5倍) < C2(提升10-100倍),总的目标是发现热点代码(hotspot名称的由来),优化之。
可以使用 -XX:-DoEscapeAnalysis 关闭逃逸分析。通过逃逸分析后的对象,可将这些对象直接在栈上进行分配,而非堆上。极大的降低了GC次数,从而提升了程序整体的执行效率。
方法内联 1 2 3 4 private static int square (final int i) { return i * i; } System.out.println(square(9 ));
如果发现 square 是热点方法,并且长度不太长时,会进行内联,所谓的内联就是把方法内代码拷贝、
1 System.out.println(9 * 9 );
例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class JIT2 { public static void main (String[] args) { int x = 0 ; for (int i = 0 ; i < 500 ; i++) { long start = System.nanoTime(); for (int j = 0 ; j < 1000 ; j++) { x = square(9 ); } long end = System.nanoTime(); System.out.printf("%d\t%d\t%d\n" ,i,x,(end - start)); } } private static int square (final int i) { return i * i; } }
字段优化 读取优化:
即时编译器会优化 实例字段 和 静态字段 的访问,以 减少总的内存访问次数
即时编译器将 沿着控制流 ,缓存各个字段 存储节点 将要存储的值,或者字段 读取节点 所得到的值
当即时编译器 遇到对同一字段的读取节点 时,如果缓存值还没有失效,那么将读取节点 替换 为该缓存值
当即时编译器 遇到对同一字段的存储节点 时,会 更新 所缓存的值
当即时编译器遇到 可能更新 字段的节点时,它会采取 保守 的策略, 舍弃所有的缓存值
方法调用节点 :在即时编译器看来,方法调用会执行 未知代码
内存屏障节点 :其他线程可能异步更新了字段
存储优化:
如果一个字段先后被存储了两次,而且这 两次存储之间没有对第一次存储内容读取 ,那么即时编译器将 消除 第一个字段存储
实例 JMH 基准测试依赖
1 2 3 4 5 6 7 8 9 10 11 <dependency > <groupId > org.openjdk.jmh</groupId > <artifactId > jmh-core</artifactId > <version > ${jmh.version}</version > </dependency > <dependency > <groupId > org.openjdk.jmh</groupId > <artifactId > jmh-generator-annprocess</artifactId > <version > ${jmh.version}</version > <scope > provided</scope > </dependency >
基准测试代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 @Warmup(iterations = 2, time = 1) @Measurement(iterations = 5, time = 1) @State(Scope.Benchmark) public class Benchmark1 { int [] elements = randomInts(1_000 ); private static int [] randomInts(int size) { Random random = ThreadLocalRandom.current(); int [] values = new int [size]; for (int i = 0 ; i < size; i++) { values[i] = random.nextInt(); } return values; } @Benchmark public void test1 () { for (int i = 0 ; i < elements.length; i++) { doSum(elements[i]); } } @Benchmark public void test2 () { int [] local = this .elements; for (int i = 0 ; i < local.length; i++) { doSum(local[i]); } } @Benchmark public void test3 () { for (int element : elements) { doSum(element); } } static int sum = 0 ; @CompilerControl(CompilerControl.Mode.INLINE) static void doSum (int x) { sum += x; } public static void main (String[] args) throws RunnerException { Options opt = new OptionsBuilder () .include(Benchmark1.class.getSimpleName()) .forks(1 ) .build(); new Runner (opt).run(); } }
首先启用 doSum 的方法内联,测试结果如下(每秒吞吐量,分数越高的更好):
1 2 3 4 Benchmark Mode Samples Score Score error Units t.Benchmark1.test1 thrpt 5 2420286.539 390747.467 ops/s t.Benchmark1.test2 thrpt 5 2544313.594 91304.136 ops/s t.Benchmark1.test3 thrpt 5 2469176.697 450570.647 ops/s
接下来禁用 doSum 方法内联
1 2 3 4 @CompilerControl(CompilerControl.Mode.DONT_INLINE) static void doSum (int x) { sum += x; }
测试结果如下:
1 2 3 4 Benchmark Mode Samples Score Score error Units t.Benchmark1.test1 thrpt 5 296141.478 63649.220 ops/s t.Benchmark1.test2 thrpt 5 371262.351 83890.984 ops/s t.Benchmark1.test3 thrpt 5 368960.847 60163.391 ops/s
分析:
1 2 3 4 5 6 7 @Benchmark public void test1 () { for (int i = 0 ; i < elements.length; i++) { sum += elements[i]; } }
可以节省 1999 次 Field 读取操作
6.2 反射优化 1 2 3 4 5 6 7 8 9 10 11 12 13 public class Reflect1 { public static void foo () { System.out.println("foo..." ); } public static void main (String[] args) throws Exception { Method foo = Reflect1.class.getMethod("foo" ); for (int i = 0 ; i <= 16 ; i++) { System.out.printf("%d\t" , i); foo.invoke(null ); } System.in.read(); } }
foo.invoke 前面 0 ~ 15 次调用使用的是 MethodAccessor 的 NativeMethodAccessorImpl 实现
当调用到第 16 次(从0开始算)时,会采用运行时生成的类代替掉最初的实现,可以通过 debug 得到
注意
sun.reflect.noInflation 可以用来禁用膨胀(直接生成 GeneratedMethodAccessor1,但首
sun.reflect.inflationThreshold 可以修改膨胀阈值